
Deploying Haskell on AWS Lambda
Originally published in IRIS Connect’s Engineering blog.
Background
At work I was put on a new project involving a low-volume application where a customer would upload some CSV files inside an S3 bucket, and this event would trigger some sort of server-side computation, to parse and validate the CSV files and produce some output. As soon as I looked at the requirements, AWS Lamba came to mind, especially because we didn’t want to maintain a server infrastructure due to the nature of the project. What tipped the scale was the fact AWS supports Lambda as one of the notification mediums to respond to an S3 event; upon seeing that my mind was set!
In a nutshell, this is the flow of the app:
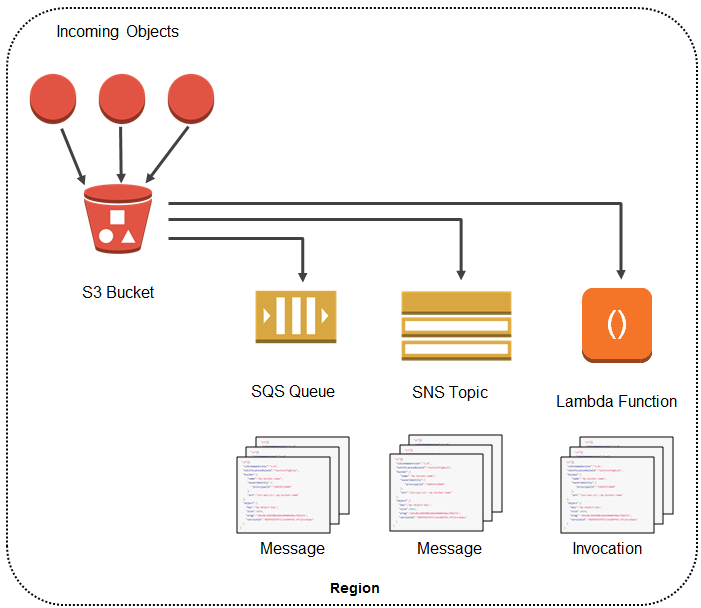
Image courtesy of Amazon
AWS Lambda is capable of running any binary, as long as it’s statically linked and compiled for x86 Linux, but at the same time it doesn’t offer first-class support for Haskell, but it’s possible to spawn an external process via the Node.js API. So the trick is to:
- Use Docker to generate a Linux executable
- Create a JS Shim to spawn a process calling our executable
- Bundle everything into a zip file (including 3rd party dependencies)
- Upload to AWS Lambda
- Watch out for any pitfalls
Needless to say that we need the Docker step because we are working on an OSX machine, whilst targeting Linux. Cross-compiling GHC for Linux is a bit of a pain, so it’s definitely way quicker to use Docker.
(Optional step) Reduce the size of the output binary
When I was working remotely from my parent’s house in Rome, I did have at my disposal only a humble domestic DSL connection, and definitely every byte mattered when it came to transfer data from my laptop into S3. This is why I’ve got into the habit of compressing my executables with UPX. The rest of the post takes that into the account, but note how such compression step is not required to deploy on AWS Lambda.
Use Docker to generate a Linux executable
We can use a script from the process outlined in my personal blog.
It basically creates a new Docker Image called “ghc-linux-6.5-builder” using Build.plan as the Docker file. Build.plan itself is quite simple:
FROM fpco/stack-build:lts-6.5
ADD . /usr/lib/haskell
WORKDIR /usr/lib/haskell
USER root
# Pass SSH_KEY as argument.
ARG SSH_KEY
# Specify a specific private key.
RUN echo " IdentityFile /root/.ssh/id_rsa" >> /etc/ssh/ssh_config
# Skip host verification for GitHub
RUN echo "Host github.com\n\tStrictHostKeyChecking no\n" >> /etc/ssh/ssh_config
# Create SSH_KEY inside container.
RUN echo "$SSH_KEY" >> /root/.ssh/id_rsa
# Give private key correct permissions.
RUN chmod 0600 /root/.ssh/id_rsa
# Give private key correct permissions.
RUN chmod 0600 /root/.ssh/id_rsa
CMD ["stack"]We are starting from the lts-6.5 Docker image FPComplete is providing us (which already includes all the system
libraries that all the LTS 6.5 deps will need to link against) plus adding our own .ssh/id_rsa to make sure
we can clone stuff from GitHub (this passage is optional and should only be required if we clone stuff from
private repositories). Note that we are using a somewhat outdated LTS revision as with newer ones using GHC 8 I
was getting an error whilst installing GHC (seemed a problem related to the toolchain), which unfortunately I
didn’t have time to investigate further. Once everything has built correctly, we can simply alias
stack-linux to be an invocation of the stack command via this newly built Docker image:
#!/usr/bin/env bash
eval $(docker-machine env)
docker run --rm \
-v $PWD/linux-dist:/root/.local \
-v $PWD/.stack-work:/usr/lib/haskell/.stack-work \
-v $HOME/.stack:/root/.stack \
ghc-linux-6.5-builder:latest stack --allow-different-user $@You can see we are targeting an OSX machine, due to the call to docker-machine.
Mapping host directories like $HOME/.stack will also ensure we will be caching packages built from one invocation
to the other, making the process much quicker overall. So, to summarise, when we call build_linux what really
happens is that we are first creating the new Docker image (or updating it), and finally calling stack-linux install
as we would normally do on our local machine, but the cool thing here is that the build is going to happen
on the Docker container and due to the fact we mounted the output of the install to linux-dist on our
local machine, at the end of the process we will have a nice Linux binary ready to be deployed on AWS Lambda!
Here is how build_linux.sh is structured:
#!/usr/bin/env bash
eval $(docker-machine env)
docker build --build-arg SSH_KEY="$(cat ~/.ssh/id_rsa)" -t ghc-linux-6.5-builder -f Build.plan .
./bin/stack-linux install
upx linux-dist/bin/ma-csv-procAfter everything ran successfully, we have our final executable ready to be deployed:
☁ mathematica-csv-processor [issue-4] du -h linux-dist/bin/ma-csv-proc
2.6M linux-dist/bin/ma-csv-procSo 2.6MB is not bad at all for a full Haskell app which deserialise JSON from the network and parse CSV files!
Create a JS Shim (the Main Handler)
In order for AWS Lambda to run our code, we need an entrypoint, which we cannot write in Haskell as AWS Lambda doesn’t have first-class support for it. What we can do, though, is to create one using JavaScript and Node, and use the Node.js process API to spawn our executable:
const spawn = require('child_process').spawn;
exports.handler = function(event, context) {
process.env['PATH'] = process.env['PATH'] + ':' + process.env['LAMBDA_TASK_ROOT']
process.env['LD_LIBRARY_PATH'] = process.env['LAMBDA_TASK_ROOT']
const main = spawn('./ma-csv-proc', { stdio: ['pipe', 'pipe', process.stderr] });
main.stdout.on('data', function(data) {
console.log(data.toString());
context.done(null, data.toString());
});
main.on('close', function(code) {
console.log('child process pipes closed with code '+ code);
context.done(null, code);
});
main.on('exit', function(code){
console.error('exit: ' + code);
context.done(null, code);
});
main.on('error', function(err) {
console.error('error: ' + err);
context.done(null, err);
});
main.stdin.write(JSON.stringify({
'event': event,
'context': context
}) + '\n');
}Note something important: we are passing the event and the context that AWS sends us as a JSON into the stdin of
our Haskell app. This ensure we can deserialise it on the Haskell side and grab the event AWS sent us, so we can
react to it:
{-# LANGUAGE TemplateHaskell #-}
{-# LANGUAGE ScopedTypeVariables #-}
module Main where
import Data.Aeson as JSON
import qualified Data.Text as T
data RawInput = RawInput {
event :: JSON.Value
, context :: JSON.Value
} deriving Show
deriveFromJSON defaultOptions ''RawInput
type Result = Either MathematicaException ()
main :: IO ()
main = do
raw <- T.hGetLine stdin
case JSON.eitherDecode (toS raw) of
Left e -> do
putStrLn "Error reading Lambda input."
putStrLn $ "Input was " <> toS raw
putStrLn $ "Error was " <> e
exitFailure
Right (ri :: RawInput) -> -- Do stuffBundle everything into a zip file (including 3rd party deps)
Lambdas are running (as you would expect) in a sandboxed environment, so it comes as no surprise
they don’t have all the executables you might need during your program’s execution. But not all is lost,
as it’s entirely possible to ship them as part of the final .zip we’ll deploy. The only 2 constraints is
that they should be self-contained (statically linked or otherwise) and built for Linux x86.
Believe it or not Lambda doesn’t come with the excellent aws-cli,
installed by default, so I had to package it (running it is not a problem as AWS Lambda uses IAM roles so permissioning is taken care of automatically).
There is an excellent post about bundling aws-cli
for AWS Lambda so I will simply redirect there for completeness.
Once we have everything we need, we can simply run a simple script to bundle everything up:
#!/usr/bin/env bash
mkdir -p deploy/aws-lambda/artifacts
rm -rf deploy/aws-lambda/artifacts/*
cd deploy/aws-lambda
zip -r -j artifacts/mathematica-csv-processor.zip Main.js aws ../../linux-dist/bin/ma-csv-proc
# Add aws stuff
zip -ur artifacts/mathematica-csv-processor.zip aws-cli
cd ../..It’s very important to run the first command with -j which will “squash” relative paths and will ensure the
binary and the JS entrypoint will be at the top level of the zip file, which is required by AWS Lambda in order
to access our code correctly. Now the fun part, deploying!
Upload to AWS Lambda
Uploading to AWS Lambda is quite simple. All is needed is for the user to create a new Lambda and then upload the zip file, either from S3 or from a web form:

Pitfalls
After deploying a new revision of the app, I was presented with a quite laconic error in the CloudWatch logs:
c_poll: Permission DeniedThere seems to be a few issues
mentioning it explicitly, and none of them explaining what’s going on. It seems to be
a GHC bug, but I’m not 100% sure (as that trac ticket claims is fixed).
What’s sure is that c_poll is coming from GHC. Luckily for me, in order to “fix” the problem, it was sufficient to
simply allocate more memory for my lambda, or increase the timeout for the program execution.
With 256/512 MB I was able to comfortably running my code under 10 seconds.
Credits
More of the information I present here are not novel; I have shamelessly stolen ideas and concepts from these two excellent resources: